Vektorová vs relačná DB: nenahrádzajú sa. Decision guide pre AI éru
Päť klientov mi za posledný rok prišlo so záverom 'potrebujeme vektorovú DB pre AI'. Štyria z nich ju nepotrebovali. Piaty áno — ale použil ju zle. Decision guide pre firmy ktoré nemajú čas na hype a chcú vedieť čo si reálne kúpiť.
Vektorová vs relačná DB: nenahrádzajú sa. Decision guide pre AI éru
Prečo táto otázka teraz horí
Za posledný rok mi prišlo päť klientov so záverom: "potrebujeme vektorovú DB pre AI." Štyria z nich ju nepotrebovali — ich problém zvládla obyčajná Postgres. Piaty ju potreboval, ale použil ju zle a vyrobil chatbot ktorý odpovedal sémanticky podobne, no fakticky inak.
Tá otázka tu je preto, lebo predaj okolo AI tlačí firmy k jednoduchému naratívu: AI = embeddings = vector DB = Pinecone. Realita je menej priamočiara. Vektorová a relačná databáza sa nenahrádzajú. Riešia odlišné typy otázok. Vo väčšine real-world stackov spolu žijú — a tretí svet, full-text search, sa zabudne, hoci v slovenských firmách často nesie najviac vyhľadávania — len o ňom nikto nehovorí.
Tento článok je decision guide. Žiadne benchmarky, žiadny rebríček. Štyri reálne situácie ktoré stretávam, tri pasti ktoré opakovane vidím u klientov, jeden default stack pre 90 % SME a tri otázky ktoré si položte predtým, ako siahnete po čomkoľvek inom než PostgreSQL.
Rámec: tri svety, nie dva
Tri typy DB, tri typy dotazov:
Relačná databáza (PostgreSQL, MariaDB, MS SQL) odpovedá presne na presné otázky. "Daj mi všetky faktúry klienta 042 z marca." Index je B-tree, dotaz je SQL, výsledok je deterministický. Toto je jadro každého business systému posledných 30 rokov.
Vektorová databáza (pgvector, Qdrant, Weaviate, Pinecone) odpovedá podobne na nepresné otázky. "Nájdi dokumenty sémanticky podobné formulácii 'ako reklamujem produkt'." Pod kapotou ukladá embeddings — číselné vektory ktoré reprezentujú význam textu — a hľadá najbližšie cez kosínusovú podobnosť. Výsledok nie je deterministický v zmysle SQL, je najpravdepodobnejšie relevantný.
Full-text search (PostgreSQL tsvector, Elasticsearch, OpenSearch) je tretí svet ktorý sa zabúda. Hľadá na úrovni slov a fráz s rankovaním podľa BM25. "Nájdi dokumenty obsahujúce slová 'reklamácia' alebo 'vrátenie' okrem tých z roku 2022." Lacný, rýchly, predvídateľný — a často je to čo používateľ skutočne potrebuje.
Väčšina real-world riešení potrebuje dve z týchto troch. Niekedy tri. Otázka nie je ktorú DB, ale aký dotaz robia moji používatelia.
Štyri reálne situácie z praxe
1. Klasický business softvér (POHODA, e-shop, CRM) — relačná stačí
Faktúry, objednávky, stavy zásob, kontakty, mzdové údaje. Každý dotaz má presnú formu: kto, kedy, koľko. Žiadna fuzzy logika nepomôže — keď účtovníčka hľadá faktúru 2024/0042, nechce sémanticky podobnú, chce tú jednu.
Default: PostgreSQL. Ak máte legacy MariaDB alebo MS SQL, nemigrujte len kvôli AI hype. Indexovať a opraviť pomalé queries dáva 10× väčší prínos než akákoľvek vektorová DB. Nepotrebujete vector len preto, že chcete dashboard alebo reportovanie do Slacku.
2. Chatbot nad firemnými PDF / interná knowledge base — vector áno
Klient chce: "spýtaj sa nášho HR manuálu". Používateľ formuluje voľne: "kedy mám nárok na PN?", "čo s otcovskou?", "kto mi schvaľuje dovolenku?". Vector DB tu robí ťažkú prácu — embeddings z relevantných pasáží sa porovnávajú s embedding-om otázky, top-3 chunks sa pošlú do LLM ako kontext.
Default: pgvector v existujúcej Postgres. Pre 90 % use-cases je to dosť. Až pri 10M+ chunkoch alebo SLA pod 50 ms začne mať zmysel siahnuť po dedikovanom engine (Qdrant, Weaviate). O tom v sekcii 5.
3. Vyhľadávanie v e-shope alebo helpdesku — hybrid
Toto je najčastejší real-world prípad ktorému zákazník zle rozumie. Používateľ na e-shope píše: "červené topánky do 80 eur veľkosť 42". Real query má tri vrstvy:
Keyword ("červené", "topánky") → BM25 / tsvector.
Sémantika (synonymá, kontext, preklepy) → vector.
Filter (cena ≤ 80, veľkosť = 42) → SQL WHERE.
Vector DB samostatne tu nestačí. Vrátiť 50 sémanticky podobných topánok všetkých farieb a cien znamená frustrovaného zákazníka. Hybrid = BM25 + vector + filter cez SQL. PostgreSQL toto všetko vie nasadiť v jednom engine — pgvector + tsvector + bežné indexy. Bez troch oddelených externých služieb.
4. AI agenti s dlhou pamäťou — vector + TTL
Agent ktorý si pamätá konverzácie z minulých týždňov, alebo systém ktorý učí z field interakcií. Vector DB áno — embeddings pamäte umožnia find-similar pri nových otázkach. Ale bez TTL stratégie (time-to-live, automatické mazanie po N dňoch) DB naberie šum. Po troch mesiacoch agent retrieval-uje irelevantné staré epizódy a halucinuje.
Pravidlo palca: každý zápis dostane TTL. Iné okná pre iné typy spomienok — systémové preferencie 365 dní, konverzačná pamäť 30 dní, transakčný kontext 7 dní. Toto je častejšia príčina zlej UX než zlý model.
Tri pasti ktoré opakovane vidím
Past 1: Vendor lock-in cez Pinecone (alebo iný proprietárny SaaS)
Pinecone je dobrá služba. Lenže keď viažete kritickú časť stacku na proprietárny endpoint bez exportu vo formáte ktorý vie iný engine prečítať, viažete sa nielen na ich pricing, ale aj na ich feature roadmap.
Konkrétny príklad ktorý sa stal v Q1 2026: Pinecone 2.0 zdvihol read costs z $0.04 na $0.12 per 1M RU — 3× nárast bez zmeny workloadu. Klienti ktorí v 2024 podpísali multi-year contract sa zobudili s trojnásobnou faktúrou a žiadnym mechanizmom downgrade-u — serverless tier znamená "platíš za usage", neexistuje menší plán na ktorý by sa dalo prejsť. Toto nie je hypotetické riziko, toto je tento rok.
Spočítajte si total cost na 3 roky vrátane re-embeddingu pri prípadnej migrácii. Často vyjde lacnejšie self-hosted pgvector na Hetzneri vrátane DevOps réžie. Konkrétne čísla nižšie v sekcii 5.
Past 2: Vector DB ako jediný zdroj pravdy
Klient — slovenský e-shop, ~30k objednávok ročne — postavil chatbot pre customer support. Cieľ: zákazník napíše otázku, dostane odpoveď s odkazom do FAQ alebo do detailu vlastnej objednávky. Tím urobil to čo dnes robí každý: FAQ + reklamačný poriadok + návody → embeddings → Pinecone → GPT-4. Pekne to fungovalo na demo otázkach.
Spadlo to v produkcii prvú hodinu. Zákazníci začali pýtať: "kde je moja objednávka 2024/0042?". Chatbot vracal sémanticky podobné texty z FAQ — "ako sledovať balík", "životný cyklus objednávky". Lebo objednávka 2024/0042 v Pinecone nebola. Bola v Postgres.
Lekcia: vector DB je o sémantike. Keď používateľ pýta fakt, potrebujete nástroj ktorý zavolá SQL. Vector hľadá podobné, nie presné. Bez relačnej DB lepíte fakty zo sémantického špása.
Riešenie zabralo dve hodiny. Pridali sme tool calling do GPT — ak otázka obsahuje vzor čísla objednávky alebo identifikátor, agent hodí parametrizovaný SELECT do Postgres. Pre kontext zostal vector. Pre fakty sa použil zdroj faktov.
Past 3: Embedding model bez verzionovania
Vyembeddujete 5 miliónov chunkov modelom OpenAI text-embedding-3-small. O šesť mesiacov vyjde lepší alebo lacnejší model. Ak nemáte verziu modelu uloženú spolu s každým vektorom — a stratégiu re-embeddingu — vyhodíte celý DB. Alebo horšie: necháte v ňom mix dvoch modelov a vyhľadávanie sa nedá dôverovať.
Pravidlo: každý zápis ukladajte s embedding_model_version. Migráciu robte ako batch job s dvojitým indexom (starý + nový), prepnite atomicky.
1ALTER TABLE chunks ADD COLUMN embedding_model_version text NOT NULL;23CREATE INDEX ON chunks USING hnsw (embedding vector_cosine_ops)4 WHERE embedding_model_version = 'text-embedding-3-small';
Partial index nad konkrétnou verziou modelu — nový model nahodíte paralelne, queries ostanú deterministické (WHERE embedding_model_version = '...' v každom dotaze), prepnete keď máte re-embedding hotový.
Default stack pre 90 % slovenských SME
Pre malú a strednú slovenskú firmu ktorá chce nasadiť AI nad firemnými dátami mám jeden default:
PostgreSQL 16+ s pgvector + tsvector na vlastnom serveri alebo cez managed (Supabase, Neon).
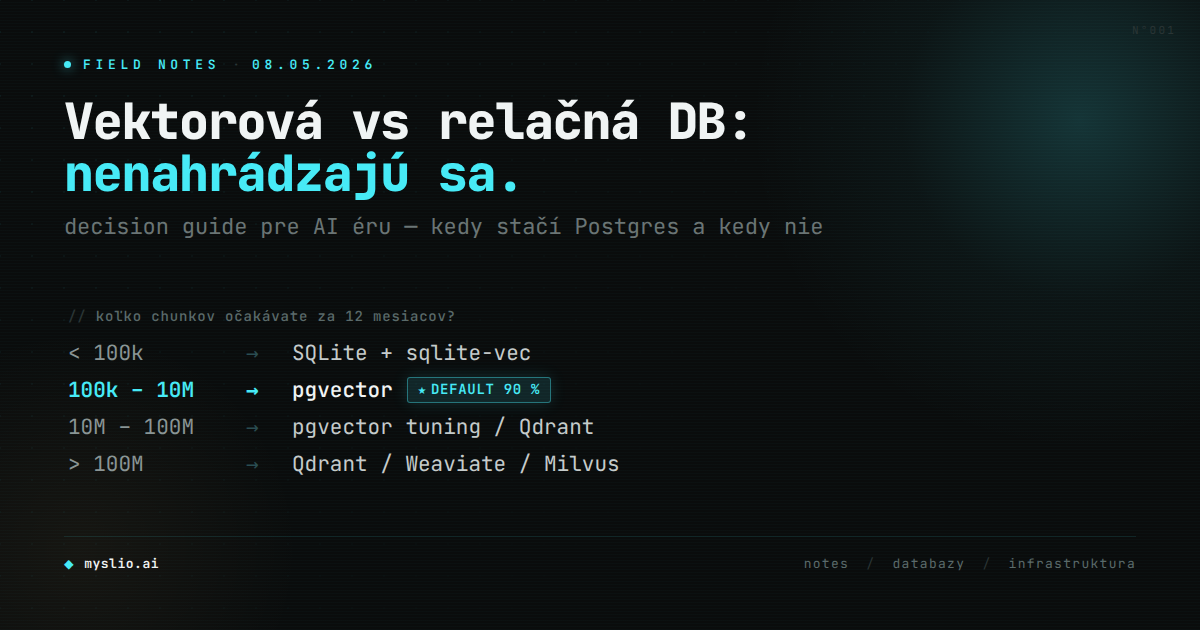
Decision tree podľa očakávaného škálovania:
1Koľko chunkov očakávate za 12 mesiacov?23 < 100k → SQLite + sqlite-vec4 (lokálne, dev, edge nasadenia)56 100k – 10M → PostgreSQL + pgvector ← default 90 % prípadov7 (Hetzner ~17 €/mes alebo Supabase Pro ~25 USD)89 10M – 100M → pgvector s tuningom (HNSW, partitioning)10 alebo migrácia na Qdrant self-hosted1112 > 100M → Qdrant / Weaviate / Milvus13 (vtedy už máte dedikovaný DB tím, ktorý si vyberie sám)
Konkrétne čísla — porovnanie pre 1 milión chunkov a mierny traffic (~5 RPS, requests per second):
Stack: PostgreSQL + pgvector (self-hosted) · Hosting: Hetzner CCX13 (2 vCPU AMD, 8 GB RAM, 80 GB NVMe) + storage box pre backupy · Mesačný náklad: ~17 €
Stack: PostgreSQL + pgvector (managed) · Hosting: Supabase Pro · Mesačný náklad: ~25 USD
Stack: Pinecone Serverless (Standard plan) · Hosting: Pinecone · Mesačný náklad: 50 USD minimum commitment, typicky 70–200 USD podľa traffic-u
Pinecone Standard má od 2024 minimum commitment 50 USD/mes. Reálna faktúra sa pri 1M chunkov a stredne aktívnom AI agentovi pohybuje 70–200 USD/mes podľa pomeru reads/writes a storage (storage 0.33 USD/GB, reads 8.25 USD per 1M RU — read units, writes 2 USD per 1M WU — write units). Pri produkčnom workloade s peak hours sa čísla šplhajú vyššie — Q1 2026 navýšenie read costs (3×) toto ešte zhoršilo.
Self-hosted pgvector na Hetzneri vás teda stojí zlomok ceny Pinecone-u. Pri vyšších loadoch je rozdiel ešte výraznejší. Navyše dáta zostávajú na infraštruktúre nad ktorou máte plnú kontrolu — 100 % access logov, žiadne tretie strany v supply chaine, žiadne prekvapenia v ToS keď vendor príde s novým pricing modelom.
Kedy migrovať preč od pgvector:
Prerástli ste 10 miliónov chunkov a zároveň potrebujete sub-50 ms latenciu na top-K queries.
Vyhľadávanie tvorí 60 %+ infra nákladu a chcete dedikovaný vector engine s nižšou per-vector cenou (Qdrant self-hosted alebo Weaviate Cloud).
Potrebujete native multi-tenancy alebo geo-distribúciu ktorá v pgvector chýba.
V 9 z 10 prípadov toto nikdy neprerastiete. Nezakladajte rozhodnutie v roku 2026 na hypotetickom škálovaní z roku 2028.
Tri otázky pred rozhodnutím
Predtým, ako kúpite Pinecone licenciu alebo migrujete dáta, zodpovedzte si tri otázky:
1. Hľadajú moji používatelia presné záznamy alebo *podobné*? Ak presné (faktúra, kontakt, status objednávky) → relačná. Ak voľné formulácie nad textom → potrebujete vector + relačnú zároveň.
2. Stačí mi jeden DB engine, alebo potrebujem kombináciu? Vo väčšine prípadov potrebujete kombináciu (vector + SQL + niekedy full-text). PostgreSQL toto vie všetko v jednom engine. Až keď narazíte na konkrétny SLA limit, deľte.
3. Aký objem chunkov budem mať za 12 mesiacov, nie za 5 rokov? Pod 1M chunkov: pgvector triviálne. 1–10M: pgvector s HNSW indexom stále v pohode. Nad 10M: zvážte dedikovaný engine, ale spočítajte total cost vrátane DevOps.
Ak vás to zaujalo a máte konkrétny use-case ktorý chcete posúdiť — POHODA + AI, chatbot nad dokumentami, search v e-shope — viem prísť na 1-dňový infra audit. Pozrieme dáta, dotazy, plán. Bez záväzku ďalšej spolupráce. Výstup je dokument s odporúčaným stackom a 90-dňovým migračným plánom.